How does Solr query work?
Herein, how do I run a query in SOLR?
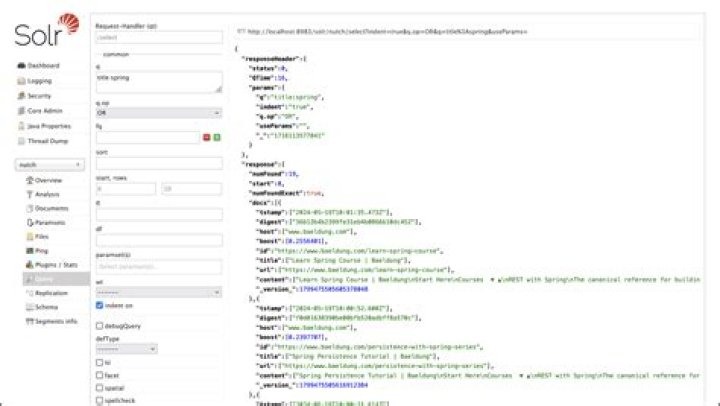
You can search for "solr" by loading the Admin UI Query tab, enter "solr" in the q param (replacing *:* , which matches all documents), and "Execute Query". See the Searching section below for more information. To index your own data, re-run the directory indexing command pointed to your own directory of documents.
Similarly, what is SOLR used for? Providing distributed search and index replication, Solr is designed for scalability and fault tolerance. Solr is widely used for enterprise search and analytics use cases and has an active development community and regular releases.
Also to know, what is SOLR query?
Apache Solr - Querying Data. Advertisements. In addition to storing data, Apache Solr also provides the facility of querying it back as and when required. Solr provides certain parameters using which we can query the data stored in it.
How does SOLR index data?
By adding content to an index, we make it searchable by Solr. A Solr index can accept data from many different sources, including XML files, comma-separated value (CSV) files, data extracted from tables in a database, and files in common file formats such as Microsoft Word or PDF.
Related Question Answers
How do I know if SOLR is installed?
You can see that Solr is running by launching the Solr Admin UI in your web browser: solr/.How do I debug SOLR?
Right click on your Solr/Lucene Java project and select Debug As and then Debug Configurations . Under the Remote Java Application category. Click New to create a new debug configuration. Enter in the port we just specified to Java at the command line – 1044.How do I stop SOLR?
Stopping Solr You can stop Solr using the stop command. This command stops Solr, displaying a message as shown below. Sending stop command to Solr running on port 8983 waiting 5 seconds to allow Jetty process 6035 to stop gracefully.How do I start SOLR?
Start the Server If you are running Windows, you can start Solr by running binsolr. cmd instead. This will start Solr in the background, listening on port 8983. When you start Solr in the background, the script will wait to make sure Solr starts correctly before returning to the command line prompt.How do I find my SOLR version?
On the Solr Admin page click on [INFO]. The next screen will have the version. you'll retrieve a structure in many different representations (xml, json, php, python,). the lucene key of the structure contains version numbers.How do I connect to SOLR?
Create a Connection- Use the Connection Wizard.
- Name the Connection.
- Select the Solr driver.
- Specify the Solr URL. Provide the Solr URL, using the ZooKeeper host and port and the collection. For example, jdbc:solr://localhost:9983? collection=test.
What is a core in SOLR?
Advertisements. A Solr Core is a running instance of a Lucene index that contains all the Solr configuration files required to use it. We need to create a Solr Core to perform operations like indexing and analyzing. A Solr application may contain one or multiple cores.How do I run Solr on Windows?
If you are running Windows, you can start Solr by running binsolr. cmd instead. This will start Solr in the background, listening on port 8983. When you start Solr in the background, the script will wait to make sure Solr starts correctly before returning to the command line prompt.What is filter query in SOLR?
The fq filter query parameter in a query to Solr search is used to filter out some documents from the search result without influencing the score of the returned documents. Queries with fq parameters are cached. The fq parameter can be specified in the reauestHandler in the solrconfig.What is Lucene query?
Lucene is a query language that can be used to filter messages in your PhishER inbox. A query written in Lucene can be broken down into three parts: Field The ID or name of a specific container of information in a database. If a field is referenced in a query string, a colon ( : ) must follow the field name.Which information is specified in field type?
A field type defines the analysis that will occur on a field when documents are indexed or queries are sent to the index. A field type definition can include four types of information: The name of the field type (mandatory). An implementation class name (mandatory).What is QF in SOLR?
The df stands for default field , while the qf stands for query fields . The field defined by the df parameter is used when no fields are mentioned in the query. The df parameter is supported by the default Solr request handler. The qf parameter is something used by the dismax query parser and the edismax query parser.What is DisMax in SOLR?
A Dismax query is nothing but a union of documents produced by the sub-queries and scores each document produced by the sub-query. In general, the DisMax query parser's interface is more like that of Google than the interface of the standard Solr request handler.What is Apache Solr tutorial?
APACHE SOLR is an Open-source REST-API based search server platform written in java language by apache software foundation. Solr is highly scalable, ready to deploy, search engine that can handle large volumes of text-centric data.What are wildcard search parameters SOLR?
Solr's standard query parser supports single and multiple character wildcard searches within single terms. Wildcard characters can be applied to single terms, but not to search phrases. The search string te?t would match both test and text. The wildcard search: tes* would match test, testing, and tester.What is SOLR and how it works?
Solr is a wrapper over Apache lucene library. It uses lucene classes to create this index known as Inverted Index. Apache Solr is a search engine. you index a set of document (say, news articles) and then query Solr to return a set of documents that matches user query.Is SOLR a NoSQL database?
Apache Solr is both a search engine and a distributed document database with SQL support. It is a NoSQL database with transactional support. It is a document database that offers SQL support and executes it in a distributed manner.Why you should use SOLR over Lucene?
Lucene is a file based indexing system, which means if an index is not located on the server that the request is coming from you have to ensure that indexes across all servers remain in sync. When you need to index large numbers of items (50,000 and up), Solr performs better. Solr is more robust.Can SOLR be used as a database?
Yes, you can use SOLR as a database but there are some really serious caveats : Furthermore, SOLR does NOT stream data --- so you can't lazily iterate through millions of records at a time. This means you have to be very thoughtful when you design large scale data access patterns with SOLR.Why SOLR is fast?
A Lucene (the underlying library used by Solr) index is made of a read-only segments. This allows Lucene to run range queries very efficiently. Since your use-case seems to leverage numeric range queries a lot, this may explain why Solr is so much faster.Does SOLR store data?
SOLR will search its own index. Data stored in SOLR is called documents (an analogy from database world is that each document is a row in a table). Before you can store data in SOLR, you will have to define a schema in a file called schema. xml (similar to a table schema in a database).Does SOLR need a database?
Almost always, the answer is yes. It needn't be a database necessarily, but you should retain the original data somewhere outside of Solr in the event you alter how you index the data in Solr. Unlike most databases, which Solr is not, Solr can't simple re-index itself. Unloading all the content from Solr can be slow.What is the difference between SOLR and Elasticsearch?
Solr is much more oriented towards text search while Elasticsearch is often used for analytical querying, filtering, and grouping. When comparing both, it's clear that Elasticsearch is a better choice for applications that require not only text search but also complex time series search and aggregations.How do I create a new core in SOLR?
Solr 4. x and later offers a helpful GUI, which provides the ability to add cores without the need to restart tomcat6. Select Core Admin from the menu on the left, then press Add Core. Fill in the name and instanceDir fields with the same name as the directory you created earlier when copying an existing core.Where is SOLR data stored?
Solr stores this index in a directory called index in the data directory.What is a SOLR index?
Apache Solr permits you to simply produce search engines that help search websites, databases, and files. Solr Indexing is like retrieving pages from a book that are associated with a keyword by scanning the index provided toward the end of a book, as opposed to looking at every word of each page of the book.Which tool can be used to put content into a SOLR instance server?
Solr includes a simple command line tool for POSTing various types of content to a Solr server. The tool is bin/post . The bin/post tool is a Unix shell script; for Windows (non-Cygwin) usage, see the Windows section below. This will contact the server at localhost:8983 .How add data to Solr?
To add the above data into Solr index, we need to prepare an XML document, as shown below. Save this document in a file with the name sample.Adding Documents Using XML
- add − This is the root tag for adding documents to the index.
- doc − The documents we add should be wrapped within the <doc></doc> tags.
How do I index a csv file in SOLR?
How to Index CSV data in Solr ?- <!--
- <field name="cat" type="text_general" indexed="true" stored="true"/>
- <field name="name" type="text_general" indexed="true" stored="true"/>
- <field name="price" type="tdouble" indexed="true" stored="true"/>
- <field name="inStock" type="boolean" indexed="true" stored="true"/>