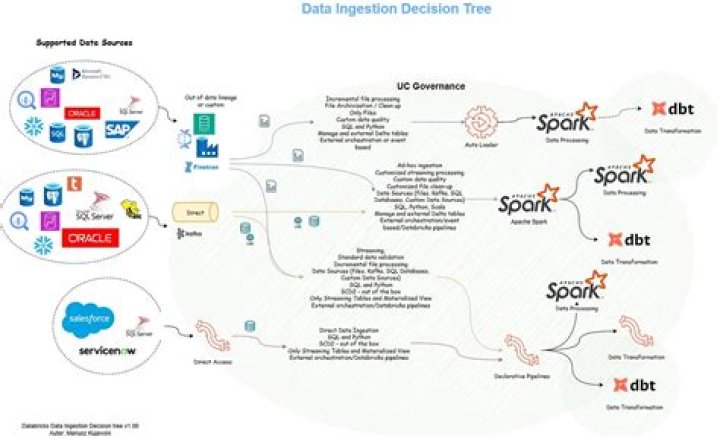
How does data ingestion work in Hadoop?
Also to know is, which is data ingestion tools in Hadoop?
The following are currently some of the other most popular tools for the job:
- Apache NiFi (a.k.a. Hortonworks DataFlow) Both Apache NiFi and StreamSets Data Collector (detailed below) are Apache-licensed open-source tools.
- StreamSets Data Collector (SDC)
- Gobblin.
- Sqoop.
- Flume.
- Kafka.
Similarly, what is data ingestion in big data? Data ingestion is the transportation of data from assorted sources to a storage medium where it can be accessed, used, and analyzed by an organization. The destination is typically a data warehouse, data mart, database, or a document store.
Then, what is your understanding of data ingestion and integration?
Data integration is the process of combining data from different sources into a single, unified view. Integration begins with the ingestion process, and includes steps such as cleansing, ETL mapping, and transformation. The data is extracted from the sources, then consolidated into a single, cohesive data set.
What is the relation between Hadoop and Big Data?
Definition: Hadoop is a kind of framework that can handle the huge volume of Big Data and process it, whereas Big Data is just a large volume of the Data which can be in unstructured and structured data. 5. Developers: Big Data developers will just develop applications in Pig, Hive, Spark, Map Reduce, etc.
Related Question Answers
What are data ingestion tools?
Data ingestion tools provide a framework that allows companies to collect, import, load, transfer, integrate, and process data from a wide range of data sources. They facilitate the data extraction process by supporting various data transport protocols.What are Hadoop tools?
Top 20 essential Hadoop tools for crunching Big Data- Hadoop Distributed File System. The Hadoop Distributed File System (HDFS) is designed to store very large data sets reliably, and to stream those data sets at high bandwidth to user applications.
- Hbase.
- HIVE.
- Sqoop.
- Pig.
- ZooKeeper.
- NOSQL.
- Mahout.
Which tool can process any kind of data?
Best Big Data Tools and Software| Name | Price | Link |
|---|---|---|
| Hadoop | Free | Learn More |
| HPCC | Free | Learn More |
| Storm | Free | Learn More |
| Qubole | 30-Days Free Trial + Paid Plan | Learn More |
In which all languages you can code in Hadoop?
Hadoop framework is written in Java language, but it is entirely possible for Hadoop programs to be coded in Python or C++ language.What is data ingestion pipeline?
A data ingestion pipeline moves streaming data and batched data from pre-existing databases and data warehouses to a data lake. For an HDFS-based data lake, tools such as Kafka, Hive, or Spark are used for data ingestion. Kafka is a popular data ingestion tool that supports streaming data.Which tool could be used to move data from Rdbms data to HDFS?
SqoopWhat is API ingestion?
Streaming ingestion lets users send data to Platform in real time from client and server-side devices.What is data ingestion in Azure?
Data ingestion is the process used to load data records from one or more sources to import data into a table in Azure Data Explorer. Once ingested, the data becomes available for query. Data is batched or streamed to the Data Manager.What is data ingestion layer?
The data ingestion layer processes incoming data, prioritizing sources, validating data, and routing it to the best location to be stored and be ready for immediately access. Data extraction can happen in a single, large batch or broken into multiple smaller ones.How do you integrate data?
How to Plan and Setup System Data Integration in 5 Easy Steps- Step 1: Determine how your data should sync.
- Step 2: Inputting your data into an integration system (choosing the right system for you)
- Step 3: Map your systems, objects and fields.
- Step 4: Refine your integration by setting up filters.
- Step 5: Start your integration - sync historical data or start fresh?
What is data integration with example?
Data integration definedFor example, customer data integration involves the extraction of information about each individual customer from disparate business systems such as sales, accounts, and marketing, which is then combined into a single view of the customer to be used for customer service, reporting and analysis.
What is data ingestion in machine learning?
Data ingestion is the process in which unstructured data is extracted from one or multiple sources and then prepared for training machine learning models. Automating this effort frees up resources and ensures your models use the most recent and applicable data.Why do we integrate data?
Data integration allows businesses to combine data residing in different sources to provide users with a real-time view of business performance. As a strategy, integration is the first step toward transforming data into meaningful and valuable information.What do you mean by data integration?
Data integration is the combination of technical and business processes used to combine data from disparate sources into meaningful and valuable information. A complete data integration solution delivers trusted data from various sources to support a business-ready data pipeline for DataOps.What does a data lake do?
Data Lakes allow you to import any amount of data that can come in real-time. Data is collected from multiple sources, and moved into the data lake in its original format. This process allows you to scale to data of any size, while saving time of defining data structures, schema, and transformations.What is big data testing?
Big Data Testing is a testing process of a big data application in order to ensure that all the functionalities of a big data application works as expected. The goal of big data testing is to make sure that the big data system runs smoothly and error-free while maintaining the performance and security.How do you profile data?
Data profiling involves:- Collecting descriptive statistics like min, max, count and sum.
- Collecting data types, length and recurring patterns.
- Tagging data with keywords, descriptions or categories.
- Performing data quality assessment, risk of performing joins on the data.
- Discovering metadata and assessing its accuracy.
How does data pipeline work?
It can process multiple data streams at once. Regardless of whether it comes from static sources (like a flat-file database) or from real-time sources (such as online retail transactions), the data pipeline divides each data stream into smaller chunks that it processes in parallel, conferring extra computing power.What is big big data?
Put simply, big data is larger, more complex data sets, especially from new data sources. These data sets are so voluminous that traditional data processing software just can't manage them. But these massive volumes of data can be used to address business problems you wouldn't have been able to tackle before.What is data pipeline architecture?
A data pipeline architecture is a system that captures, organizes, and routes data so that it can be used to gain insights. Raw data contains too many data points that may not be relevant. Data pipeline architecture organizes data events to make reporting, analysis, and using data easier.What is another word for ingestion?
In this page you can discover 14 synonyms, antonyms, idiomatic expressions, and related words for ingestion, like: mouth, gulp, swallow, consumption, intake, uptake, inhalation, ingest, excretion, dehydration and aerosolised.How we can use big data in recommender systems?
Filtering means filtering products based on ratings and other user data. Recommendation systems use three types of filtering: collaborative, user-based and a hybrid approach. In collaborative filtering, a comparison of users' choices is done and recommendations given.Which has the world's largest Hadoop cluster?
FacebookWhat is an ingest?
When you ingest something, you swallow it or otherwise consume it. You can also use this word to mean "take in information," like when you ingest the details of your history book. Ingest has a Latin root, ingestus, "poured in," from in-, "into," and gerere, "to carry."What is difference between Hadoop and Spark?
It's also a top-level Apache project focused on processing data in parallel across a cluster, but the biggest difference is that it works in-memory. Whereas Hadoop reads and writes files to HDFS, Spark processes data in RAM using a concept known as an RDD, Resilient Distributed Dataset. Spark has several APIs.Is Hadoop part of big data?
Hadoop is an open source, Java based framework used for storing and processing big data. The data is stored on inexpensive commodity servers that run as clusters. Cafarella, Hadoop uses the MapReduce programming model for faster storage and retrieval of data from its nodes.What are the big data tools?
8 Big Data Tools You need to Know- Hadoop.
- MongoDB.
- Cassandra.
- Drill.
- Elastisearch.
- HCatalog.
- Oozie.
- Storm.
What is the difference between Hadoop and Apache Hadoop?
Apache Hadoop: It is an open-source software framework that built on the cluster of machines. It is used for distributed storage and distributed processing for very large data sets i.e. Big Data.Difference Between Big Data and Apache Hadoop.
| No. | Big Data | Apache Hadoop |
|---|---|---|
| 6 | It defines the data set size. | It is where the data set stored and processed. |